In this article, I will summarize the important concepts from each chapter of this book and bring out the crux of what you need to know in 15 minutes. There are also additional links to keywords to help you research further.
Title: Web Scalability for Startup Engineers, 1st Edition, 2015 Author: Artur Ejsmont Amazon Link (no referral): https://www.amazon.com/Scalability-Startup-Engineers-Artur-Ejsmont/dp/0071843655
Who is this book for?
Overall, I feel that fresh or recent graduates will benefit the most as the book tries to cover a broad variety of topics instead of going in depth. Even though this book was published in 2015 and only has a single edition, much of the core concepts are still essential and relevant as we moved into the cloud era.
How is the book structured?
This book has 9 chapters and is mainly written from the perspective of an engineer working in a tech startup with scalability in mind. The book starts off with introducing the core concepts of system scalability and principles of good software design (chapter 1, 2). Following which the author introduces the front-end layer, web services, and then the data layer (chapter 3, 4, 5). Next, he talks about caching as one of the key strategies for scalability before diving into asynchronous processing and search (chapter 6, 7, 8). Lastly, he ends off with a discussion on improving engineering efficiency through automation and how to manage a tech team (chapter 9).
Main Takeaways
Chapter 1 — Core Concepts
- Scalability is the ability to adjust the capacity of the system to cost-efficiently fulfill the demands. Scalability usually means an ability to handle more users, clients, data, transactions or requests without affecting the user experience.
- Vertical scalability is accomplished by upgrading the hardware and/or network throughput. It is often the simplest solution for short-term scalability as it does not require architectural changes to your application. It can be as simple as upgrading your (virtual) server instance to a more powerful one. However, vertical scaling comes with some serious limitations, main one being cost as it becomes extremely expensive beyond a certain point.
- Locks are used to synchronize access between execution threads to shared resources like memory or files. Lock contention is a performance bottleneck caused by inefficient lock management.
- Cache is a server/service focused on reducing latency and resources needed to generate the result by serving previously generated content.
- Isolation of services is a great next step for single-server setup, as you can distribute the load among more machines than before and scale each of them vertically as needed.
- A content delivery network (CDN) is a hosted service that takes care of global distribution of static files like images, JavaScript, CSS and videos. It works as an HTTP proxy. Using CDN is not only cost effective, but often much transparent. The more traffic you generate, the more you are charged by the provider, but cost per capacity unit remains constant.
- Horizontal scalability is accomplished by a number of methods to increase capacity by adding more servers. Horizontal scalability is considered the holy grail of scalability as it overcomes the increasing cost of capacity unit associated with scaling by buying ever-stronger hardware.
- Systems should start by scaling horizontally in areas where it is the easiest to achieve, like web servers and caches, and then tackle the more difficult areas, like databases or other persistence stores.
- Round-robin DNS is a DNS server feature to resolve a single domain name to one of the many IP addresses. Round-robin DNS maps the domain name to multiple IP addresses, each IP point to a different machine. Then each time a client asks for a name resolution, DNS responds with one of the IP addresses. Goal is to direct traffic from one client to one of the web servers — different clients may be connected to different servers without realizing it. Once a client receives an IP address, it will only communicate with the selected server.
- Round-robin DNS has a few problems. You cannot remove a server out of rotation because clients might have its IP address cached. You cannot add a server to increase capacity either, because clients who have already had resolved the domain name will keep connecting to the same server. Instead, put a load balancer between web servers and clients.
- GeoDNS is a DNS service that allows domain names to be resolved to IP addresses based on the location of the customer. The goal is to direct customer to the closest data center to minimize network latency.
- Edge cache is a HTTP cache server located near the customer, allowing the customer to partially cache HTTP traffic. It is most efficient when acting as simple reverse proxy servers caching entire pages. It can also decide that the page is un-cacheable and delegate fully to your web servers.
- A load balancer (LB) is a software or hardware component that distributes traffic coming to a single IP address over multiple servers, which are hidden behind the load balancer. It is used to share the load evenly among multiple servers and allow dynamic addition or removal of those servers.
- Service-oriented architecture (SOA) is architecture centered on loosely coupled and highly autonomous services focused on solving business needs. Note: this term is probably the grandfather of micro-services.
- A multilayer architecture is a way to divide functionality into a set of layers. Components in the lower layers expose an application programming interface (API) that can be consumed by clients residing in the layers above, but you can never allow lower layers to depend on the functionality provided by the upper layers.
Chapter 2 — Principles of good software designs
- Principles of good software designs: Simplicity, Loose Coupling, Don’t Repeat Yourself (DRY), Coding to Contract, Diagrams, Single Responsibility, Open-Closed Principle, Dependency Injection, Inversion of Control (IOC), Designing for Scale, Design for Self-Healing
- Hide complexity and build abstractions. Local simplicity is achieved by ensuring that you look at any single class, module, or application and quickly understand what its purpose and how it works. A good general rule is that no class should depend on more than a few other interfaces or classes. In large and complex systems you will need to add another layer of abstraction where you create separate services. Each service becomes responsible for a subset of functionality hiding its complexity and exposing an even higher level of abstraction.
- Avoid overengineering. Good design allows you to add more details and features later on, but does not require you to build a massive solution up front. Overengineering usually happens when people try to do the right thing, but choose the wrong perspective or assume too much about future needs.
- Adopt Test-driven development (TDD) to promote simplicity. It is a set of practices where engineers write tests first and then implement the actual functionality. It is a radical approach but worth experiencing. The main benefits are that there is no code without unit tests and there is no “spare” code. Since developers write tests first, they would not add unnecessary functionality, as it would require them to write tests for it as well. It forces engineers to assume the client’s point of view first, which helps to create much cleaner and simpler interfaces.
- Keep coupling between parts of your system as low as necessary. Coupling is a measure of how much two components know about and depend on one another. The higher the coupling, the stronger the dependency. Loose coupling refers to a situation where different components know as little as necessary about each other. High coupling means that changing a single piece of code requires you to inspect in detail multiple parts of the system. Decoupling on a higher level can mean having multiple applications, with each one focused on a narrow functionality. You can then scale each application separately depending on its needs.
- Single responsibility principle states that your classes should have one single responsibility and no more. It reduces coupling, increases simplicity and makes it easier to refactor, reuse and unit test your code.
- Open-closed principle is about creating code that does not have to be modified when requirements change or when new use cases arise. Open-closed stands for “open for extension and closed for modification”. It allows us to leave more options available and delay decisions about the details. It also reduces the need to change existing code.
- Inversion of control (IOC) is a method of removing responsibilities from a class to make it simpler and less coupled to the rest of the system. At its core, inversion of control is not having to know who will create and use your objects, how or when.
Designing for scale can be boiled down to three basic design techniques:
- Adding more clones: adding indistinguishable components. To scale by adding clones, you need to pay close attention to where you keep the application state and how you propagate state changes among your clones. It works best for stateless services, as there is no state to synchronize. It is the easiest and cheapest technique to implement in your web layer.
- Functional partitioning: dividing system into smaller subsystems based on functionality. You can split your monolithic application into a set of smaller functional services. Benefits of such division is the ability to have multiple teams working in parallel on independent codebases and gaining more flexibility in scaling each service, as different services have different scalability needs.
- Data partitioning: keeping a subset of data on each machine instead of cloning entire dataset onto each machine. It is a manifestation of share-nothing principle, as each server has its own subset of data, which it can control independently. Each node is fully autonomous, and can make its own decisions about its state without the need to propagate state changes to its peers. Not sharing state means there is no data synchronization, no need for locking, and failures can be isolated because nodes do not depend on one another.
Chapter 3 — Building the Front-End Layer
- Statelessness is a property of a service, server, or object indicating that it does not hold any data (state). Instead of holding data themselves, stateless services delegate to external services any time that client’s state needs to be accessed.
Any data you put in the front end session should be stored outside to the web server itself to be available from any web server. There are some common ways to solve this problem:
- Store session state in cookie. Challenge is that cookies are sent by browser with every single request, regardless of type of resource being requested. All requests within same cookie domain will have session storage appended as part of the request. Cost of cookie-based session storage amplified by fact that encrypting serialized data and then Base64 encoding increase size of overall byte count by one third, so 1KB of session scope data becomes 1.3KB of additional data transferred with each web request and response.
- Delegate session storage to an external data store. Web application takes session identifier from web request and then load session data from an external data store. At the end of the web request life cycle, just before a response is sent back to the user, application would serialize session data and save it back in the data store. Web server does not hold any of the session data between web requests, which makes it stateless in the context of an HTTP session.
Chapter 4 — Web Services
- The key to scalability and efficient resource utilization is to allow each machine to work as independently as possible. For a machine to make progress, it should depend on as few other machines as possible. Locks are clearly against that concept, as they require machines to talk to each other or to another external system. By using locks, all of your machines become interdependent. If one process becomes slow, anyone else waiting for their locks becomes slow. When one feature breaks, all other features may break. You can use locks in your scheduled batch jobs, crons, and queue workers, but it is best to avoid locks in request-response life cycle of your web services to prevent availability issues and increase concurrency.
- A distributed transaction is a set of internal service steps and external web service calls that either complete together or fail entirely. The most common method of implementing distributed transactions is the 2 Phase Commit (2PC) algorithm
Chapter 5 — Data Layer
- Scaling using replication is only applicable to scaling reads (not writes, at least for MySQL database). Basically writes are done on a single master database and the data written is then replicated to the other slave databases. Replication lag refers to time needed for data to replicate from master to slave. It can be as low as half a second but may increase suddenly, causing inconsistency.
- Data partitioning (Sharding) is to divide the data set into smaller pieces so that it could be distributed across multiple machines and so that none of the servers would need to deal with the entire data set. Without data overlap, each server can make authoritative decisions about data modifications without communication overhead and without affecting availability during partial system failures. Here is another good explanation of sharding.
- A sharding key is the information used to decide which server is responsible for the data you are looking for. The way a sharding key is used is similar to way you interact with object caches. To get data out of the cache, you need to know the caching key, as that is the only way to locate the data. You need to have sharding key to find out which server has the data. Once you know which server has the data, you can connect to it.
- By using application-level sharding, none of the servers need to have all of the data. Each of the DB servers will have a small subset of the overall data, queries and read/write throughput. By having multiple servers, you can scale the overall capacity by adding more servers rather than by making each of your servers stronger.
- Since sharding splits data into disjointed subsets, you end up with a share-nothing architecture. There is no overhead of communication between servers and there is no need for cluster-wide synchronisation or blocking. Another advantage is that you can implement sharding on application layer and then apply it to any data store. The challenge of application-level sharding is that you cannot execute queries spanning multiple shards. Any time you want to run such a query, you need to execute parts of it on each shard and then somehow merge the results in application layer.
The term ACID transaction refers to a set of transaction properties supported by most relational database engines.
- Atomicity: atomic transaction is executed in its entirety, it either completes or is rejected and reverted.
- Consistency: guarantees that every transaction transforms the data set from one consistent state to another and that once the transaction is complete, dats conforms to all of the constraints enforced by data schema.
- Isolation: guarantees that transactions can run in parallel without affecting each other.
- Durability: guarantees that data is persisted before returning to the client so that once a transaction is completed it can never be lost, even due to server failure.
Side effect of distributing data across multiple machines is that you lose the ACID properties of your DB as a whole. If you have to update all of the orders for a particular user, you could do it within the boundaries of a single server, thus taking advantages of ACID transactions. However, if you needed to update all of the orders of a particular items, you need to send your queries to multiple servers. There will be no guarantee that all of them would succeed or all of them would fail. You could successfully execute all of the queries on Shard A, commit transaction and then fail to commit transaction on Shard B. In this case, there is no way to roll back queries executed on Shard A, as your transaction had already completed.
- Shard key is used to map to a server number. The most simplest way to map sharding key to server number by using a modulo operator.
- Problem with modulo-based mappings is that each user is assigned to a particular server based on total number of servers. If number of servers changes, most of the user-server mappings change. One way to overcome is to keep all mappings in a separate database. Rather than computing server number based on algorithm, we look up server number based on sharding key value. Side note: an improvement to modulo-based mapping is to use consistent hashing.
CAP Theorem states that it is impossible to build a distributed system that would simultaneously guarantee consistency, availability and partition tolerance.
- Consistency — ensures all nodes can see same data at the same time
- Availability — guarantees any available node can serve client requests even when other nodes fail
- Partition tolerance — ensures system can operate in the face of network failures where communication between nodes is impossible
- Eventual consistency is a property of a system where different nodes may have different versions of the data, but where state changes eventually propagate to all of the servers. If you asked a single server for data, you would not be able to tell whether you got the latest data or some older version of it because the server you choose might be lagging behind. Amazon Dynamo data store has this property.
- Some data stores use eventual consistency as a way to increase high availability. Clients do not have to wait for the entire system to be ready for them to be able to read or write. Servers accepts read and writes at all times, hoping that they will be able to replicate incoming state changes to their peers later on. Downside of such optimistic write policy is that it can lead to conflicts since multiple clients can update same data at exact same time using different servers.
- Multiple ways to resolve conflicts — simplest policy is to accept most recent write and discard earlier writes but this may lead to data lost. Another way is to push responsibility for conflict resolution to its clients. Keep all conflicting values and any time a client asks for that data, return all of the conflicted versions of the data, letting client decide how to resolve.
- To deal with edge case scenarios where different servers end up with different data, some NoSQL data stores like Cassandra employ additional self-healing strategies. For example, 10% of reads sent to Cassandra nodes trigger a background read repair mechanism. After a response is sent to the client, Cassandra node fetches requested data from all replicas and compare their values, and sends update back to any node with inconsistent or stale data.
- Quorum consistency means the majority of the replicas agree on the result. When you write using quorum consistency, majority of the servers need to confirm that they have persisted you change. Reading using a quorum, on the other hand, means that majority of the replicas need to respond so that most updated copy of the data can be found and returned to the client.
- MongoDB (distributed setup)— if primary node failed before your changes got replicated to secondary nodes, your changes would be permanently lost. In MongoDB, clients can connect to any of the servers no matter what data they intend to read or write. Clients then issue their queries to the coordinator node they chose without any knowledge about the topology or state of cluster. This is a great example of decoupling and significantly reduces complexity on application side.
- Cassandra — different rows may have different columns (fields), and may live in different servers in the cluster. Rather than defining schema up front, you dynamically create fields as they are required. To access data in any of the columns, you need to know which row you are looking for, and to locate the row, you will need its row key. Anytime you write the data, the coordinator node forwards query to all servers responsible for corresponding partition range. So although the client connects to a single server and issues a single write request, that request translates to multiple write requests, one for each of the replica holders. With quorum consistency, coordinator has to wait for at least two nodes to confirm they have persisted the change before it can return to the client.
- Cassandra loves writes and deletes are the most expensive type of operate to perform. It uses append-only data structures which allows it to write inserts with astonishing efficiency. Data is never overwritten in place and hard disks never have to perform random write operations, greatly increasing write throughput. Use case that add and deletes a lot of data can become inefficient because deletes increase data size rather than reducing it, until the compaction process cleans them up.
Chapter 6 — Caching
- Caching allows you to serve requests without computing responses, enabling you to scale much easier. Cache hit ratio is the single most important metric when it comes to caching. Cache effectiveness depends on how many times you can reuse the same cached response, which is measured in cache hit ratio.
Three factors affecting cache hit ratio:
- Data set size — cache key space is the number of all possible cache keys your application could generate. The more unique cache keys your app generates, the less chance you have to reuse any one of them. Always consider ways to reduce the number of possible cache keys. The fewer the cache keys possible, the better for cache efficiency.
- Space — number of items you can store in cache before running out of space. Depends directly on average size of objects and size of cache. Because caches are usually stored in memory, space available for cache objects is strictly limited and relatively expensive.
- Longevity — how long, on average, each object can be stored in cache before expiring or being invalidated. You can cache objects for predefined amount of time called Time to Live (TTL). The longer you cache your objects for, the higher the chance of reusing each cache object. Use cases with a high ration of reads to writes are usually good candidates for caching as cached objects can be created once and stored for longer periods of time before expiring or becoming invalidated, whereas use cases with data updating very often may render cache useless, as objects in cache may become invalidate before they are used again.
- Read-through cache is a caching component that can returned cached resources or fetch data for client if request cannot be satisfied from cache. Client connects to read-through cache rather than origin server that generates actual response.
- Browser cache is the most common type of cache. Whenever an HTTP request is about to be sent, browser checks cache for valid version of the resource and if it is present and still fresh, browser can reuse without ever sending an HTTP request.
- Caching proxy is a server install in local network or by ISP. It is a read-through cache used to reduce amount of traffic generated by users of network by reusing responses between users of the network. SSL encrypts communication between client and server, so caching proxies are not able to intercept such requests.
- Reverse proxy is a server in your data center. Can use it to override HTTP headers and better control which requests are being cached and for how long. Reverse proxies are excellent way to speed up web services layer. Open source reverse proxy solutions include Nginx, Varnish, Squid, Apache mod_proxy.
- You do not have to worry much about cache servers becoming full by setting a long TTL, as in-memory caches use algorithms designed to evict rarely access objects and reclaim space. Most commonly used algorithm is Least Recently Used (LRU), which allows cache server to eventually remove rarely access objects and keep “hot” items in memory to maximize cache hit ratio. See more here.
- Object caches are used in a different way than HTTP caches, they use cache-aside rather than read-through caches. Application needs to be aware of the existence of object cache and it can be seen by the app as an independent key-value data store. Application code will ask the object cache if the needed object is available and if so, retrieve and use the cache object. Else, build it from scratch.
- Caching rules of thumb: (1) The higher up the call stack you can cache, the more resources you can save. If you can cache an entire page fragment, you will save more time and resources than caching just the database query that was used to render this page fragment. (2) Reuse cache among users. Caching objects that are never requested again is simply a waste of time and resources.
- To prioritise what to cache, calculate the aggregated time spent in the following way: aggregated time spent = time spent per request * number of requests. This allows you to find out which pages are the most valuable when it comes to caching.
Chapter 7 — Asynchronous processing
- Asynchronous processing is about issuing requests that do not block your execution. The caller never waits idle for responses from services it depends upon. Requests are sent and processing continues without every being blocked. Blocking occurs when your code has to wait for an external operation to finish. Blocking can also occur when you synchronize multiple processes/threads to avoid race conditions.
- A callback is a construct of asynchronous processing where caller does not block while waiting for the result of the operation, but provides a mechanism to be notified once operation is finished.
- A message queue is a component that buffers and distributes asynchronous requests. A message broker is a specialized app designed for fast and flexible message queueing, routing and delivery. It is optimized for high concurrency and high throughput because being able to enqueue messages fast is one of their key responsibilities.
Message broker routing methods:
- Direct worker queue — consumers and producers only have to know the name of the queue. The queue is located by name, and multiple producers can publish to it at any point in time. Each message arriving to the queue is routed to only one consumer.
- Publish/Subscribe — messages can be delivered to more than one consumer. Consumers have to connect to the message broker and declare which topics they are interested in.
Chapter 8 — Search
- An index is structured and sorted in a specific way, optimized for particular types of searches. The data set is reduced in size because the index is much smaller in size than overall body of text so that the index can be loaded and processed faster
- Cardinality is a number of unique values stored in a particular field. Fields with high cardinality are good candidates for indexes, as they allow you to reduce data set to a very small number of rows. Low-cardinality fields are bad candidates for indexes as they do not narrow down the search enough — after traversing the index, you still have a lot of rows left to inspect.
- A compound index (composite index) is an index that contains more than one field. Use this to increase search efficiency where cardinality or distribution of values of individual fields is not good enough.
- For search engines, consistency and write performance may be much less important to them than being able to perform complex searches very fast. The core concept behind full text search and modern search engine is an inverted index. It is a type of index that allows you to search for phrases or individual words. An inverted index grows in size faster than normal index because each word in each document must be indexed.
- During search, a query is first broken down into tokens (like words) and then each of the tokens can be preprocessed (e.g. lowercase) to improve search performance. Any time you want to find documents containing particular words, you first find these words in the dictionary and then merge their posting list.
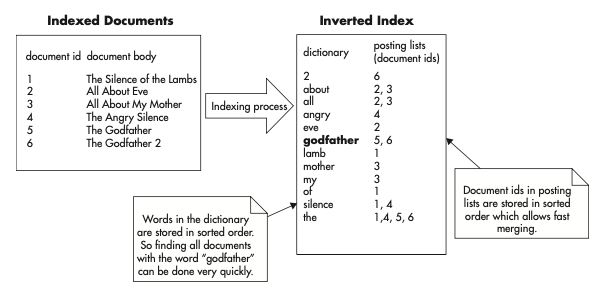
Inverted index structure
- A common pattern for indexing data in a search engine is to use a job queue. Anytime anyone modifies a metadata, they submit an asynchronous message for this particular car to be reindexed. At a later stage, a queue worker picks up the message from the queue, builds up the JSON document with all the information, and posts to the search engine to overwrite previous data.
Chapter 10 — Other Dimensions of Scalability
- Increase your availability by reducing mean time to recovery (MTTR) by automating monitoring and alerting of your systems. MTTR = Time to discover problem + Time to respond + Time to investigate + Time to fix Scaling productivity through Automation. A big part of startup philosophy is to scale the value of your company exponentially over time while keeping your costs growing at a much slower rate.
- Testing is the first thing you should automate when building a scalable web application. The overall cost of manual testing grows much faster over time than the overall cost of automated testing. Automated testing requires an up-front investment but will pay off when you get more efficient with every release.
- Majority of your tests should be unit tests where it can be executed without other components being deployed.
- Continuous integration is the first step of the automation evolution. It allows your engineers to commit to a common branch and have automated tests executed on that shared codebase any time that changes are made.
- Continuous delivery is the second step in the automation evolution. In addition to running unit tests and building software packages, the continuous delivery pipeline deploys your software to a set of test environments (usually called dev, testing, or staging).
- Continuous deployment is the final stage of the deployment pipeline evolution, where code is tested, built, deployed, and pushed to production without any human interaction.
- Use feature toggles to enable and disable selected features instantly. A feature in hidden mode is not visible to the general audience, and disabled features are not visible at all. By using feature toggles, you can quickly disable a new broken feature without redeploying any servers.
- Use A/B tests and feature toggles to test new features on a small subset of users. During the A/B testing phase, you can also gather business-level metrics to see whether a new feature is used by users and whether it improves your metrics (for example, increased engagement or user spending).
- Send application logs to a data store (or centralized log service) directly rather than logging to files. This ensures logs are independent and still available for query when the main application server is down.
- When managing a project, you have three “levers” allowing you to balance the project: scope, cost, and time. Anytime you increase or decrease the scope, cost or deadline, the remaining two variables need to be adjusted to reach a balance.
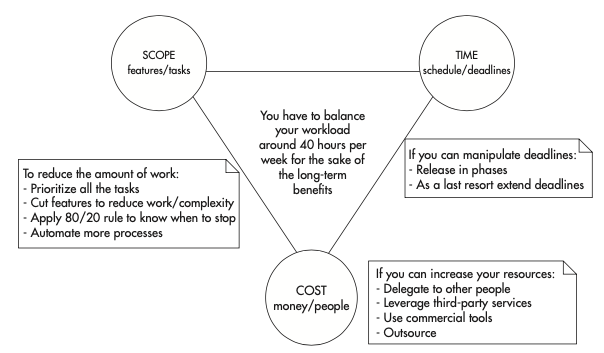
Project management levers
Conclusion
Overall, this book takes a big picture approach to scaling web systems and introduces some critical concepts that every web engineer should know. If you have come this far, I hope this summary serves you well and thanks for reading! 🤗